Gemma Embeddings: Building Efficient Vector Representations for AI Applications
Google's EmbeddingGemma enables developers to create lightweight, on-device embedding models that power semantic search, retrieval-augmented generation, and clustering tasks without relying on external APIs.
Gemma Embeddings: Building Efficient Vector Representations for AI Applications
Embeddings have become foundational to modern AI applications, transforming text and other data into numerical vectors that capture semantic meaning. Google's EmbeddingGemma framework simplifies the process of creating and deploying custom embedding models, offering developers a practical path to build efficient, on-device solutions for semantic search, retrieval-augmented generation (RAG), and clustering tasks.
What Are Embeddings and Why They Matter
Embeddings convert unstructured data—primarily text—into dense vector representations that machine learning models can process. These vectors capture semantic relationships, allowing systems to identify similar documents, answer questions by retrieving relevant context, and cluster information without explicit programming. Traditional approaches rely on closed-source APIs, introducing latency, cost, and privacy concerns. EmbeddingGemma addresses these limitations by providing an open framework for building custom embeddings.
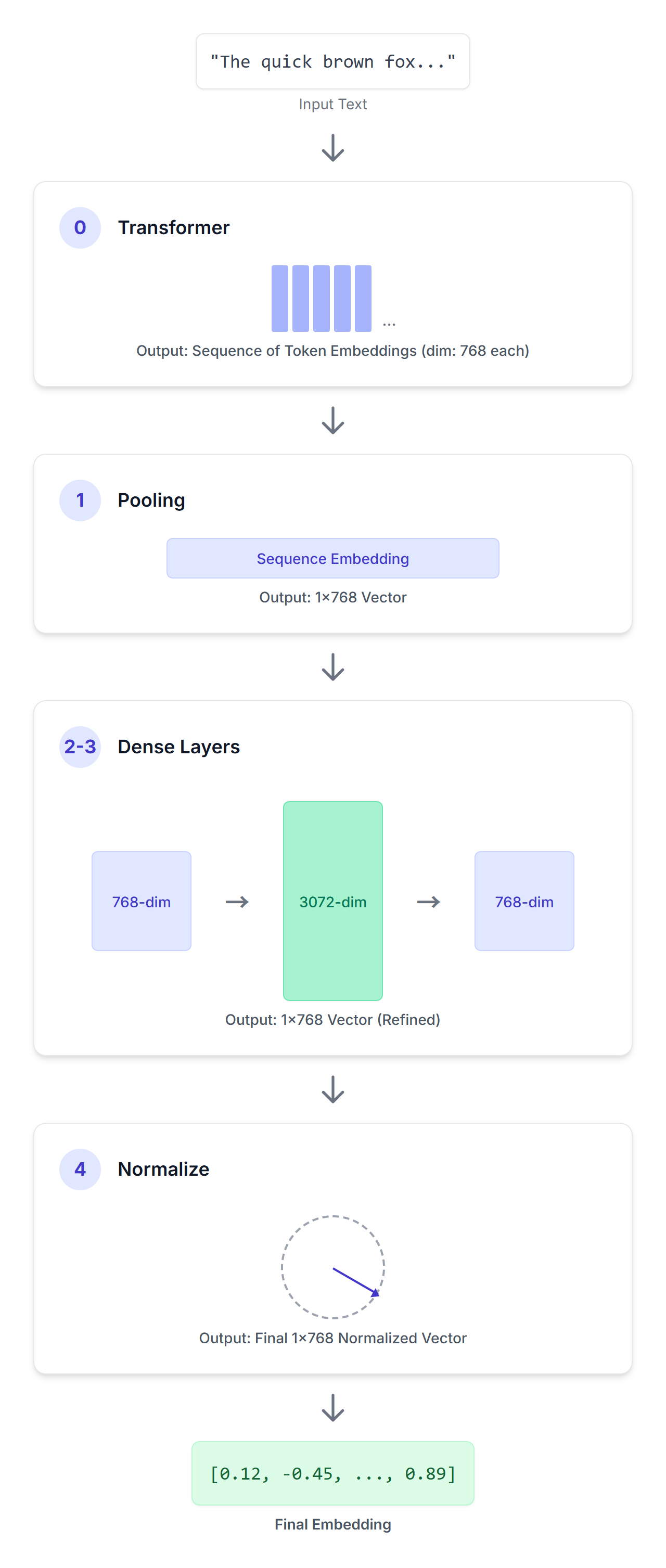
Understanding EmbeddingGemma Architecture
EmbeddingGemma builds on Google's Gemma foundation models, adapting them specifically for embedding tasks. The architecture leverages transformer-based encoders optimized for efficiency, enabling deployment on resource-constrained devices while maintaining competitive performance.
Key architectural features include:
- Lightweight design: Models sized for practical deployment without sacrificing quality
- Transformer-based encoding: Leverages proven attention mechanisms for semantic understanding
- Flexible output dimensions: Supports various embedding sizes depending on use case requirements
- On-device capability: Runs locally without external API dependencies
The framework provides pre-trained models and recipes for fine-tuning on domain-specific data, allowing developers to customize embeddings for specialized vocabularies or industry-specific terminology.
Practical Applications
Semantic Search
EmbeddingGemma powers semantic search systems that retrieve documents based on meaning rather than keyword matching. By embedding both queries and documents, systems can rank results by semantic similarity, improving search relevance.
Retrieval-Augmented Generation
RAG systems combine retrieval with language generation, using embeddings to fetch relevant context before generating responses. EmbeddingGemma enables efficient retrieval pipelines that reduce hallucinations and ground responses in factual data.
Clustering and Classification
Embeddings facilitate unsupervised clustering of similar documents and supervised classification tasks. Organizations can organize large document collections, identify duplicate content, or categorize information without manual labeling.
Implementation Considerations
Developers implementing EmbeddingGemma should consider several factors:
- Model size selection: Choose between compact and larger variants based on latency and accuracy requirements
- Fine-tuning strategy: Determine whether pre-trained embeddings suffice or if domain-specific fine-tuning improves performance
- Vector storage: Plan for efficient storage and retrieval of embeddings using vector databases
- Evaluation metrics: Measure embedding quality using standard benchmarks like NDCG for retrieval tasks
Advantages Over API-Based Solutions
EmbeddingGemma offers distinct advantages compared to cloud-based embedding services:
- Privacy: Embeddings remain on-device, protecting sensitive data
- Cost efficiency: Eliminates per-request API charges at scale
- Latency reduction: Local processing eliminates network round trips
- Customization: Fine-tune models on proprietary data without sharing information externally
- Reliability: Operates independently of external service availability
Getting Started
The Google AI developer documentation provides comprehensive guides for implementing EmbeddingGemma. Developers can access pre-trained models, training recipes, and integration examples to accelerate deployment. The framework supports multiple programming environments and integrates with popular vector databases.
Key Sources
EmbeddingGemma represents a significant step toward democratizing embedding technology, enabling organizations to build sophisticated semantic search and retrieval systems without dependency on proprietary APIs. As embeddings become increasingly central to AI applications, open frameworks like EmbeddingGemma provide the flexibility and control enterprises require.



