How LLM Steering is Reshaping AI Control and Alignment
LLM steering—a technique that guides language model behavior without retraining—is emerging as a critical tool for AI safety and control. Discover how activation steering and weight arithmetic are transforming how researchers steer AI systems.
The Race to Control Language Models
As large language models grow more powerful and autonomous, researchers face a pressing challenge: how do you guide their behavior without expensive retraining cycles? The answer lies in a rapidly advancing field called LLM steering—a set of techniques that manipulate model activations and weights to steer outputs toward desired behaviors. This approach is gaining traction across AI safety, alignment research, and practical deployment scenarios, with teams at major institutions racing to refine and scale these methods.
What is LLM Steering?
LLM steering refers to a family of techniques that modify how language models process information at runtime, without altering their underlying weights or requiring full retraining. The core idea is elegant: by understanding and manipulating the internal activations that flow through a model's layers, researchers can nudge outputs in specific directions.
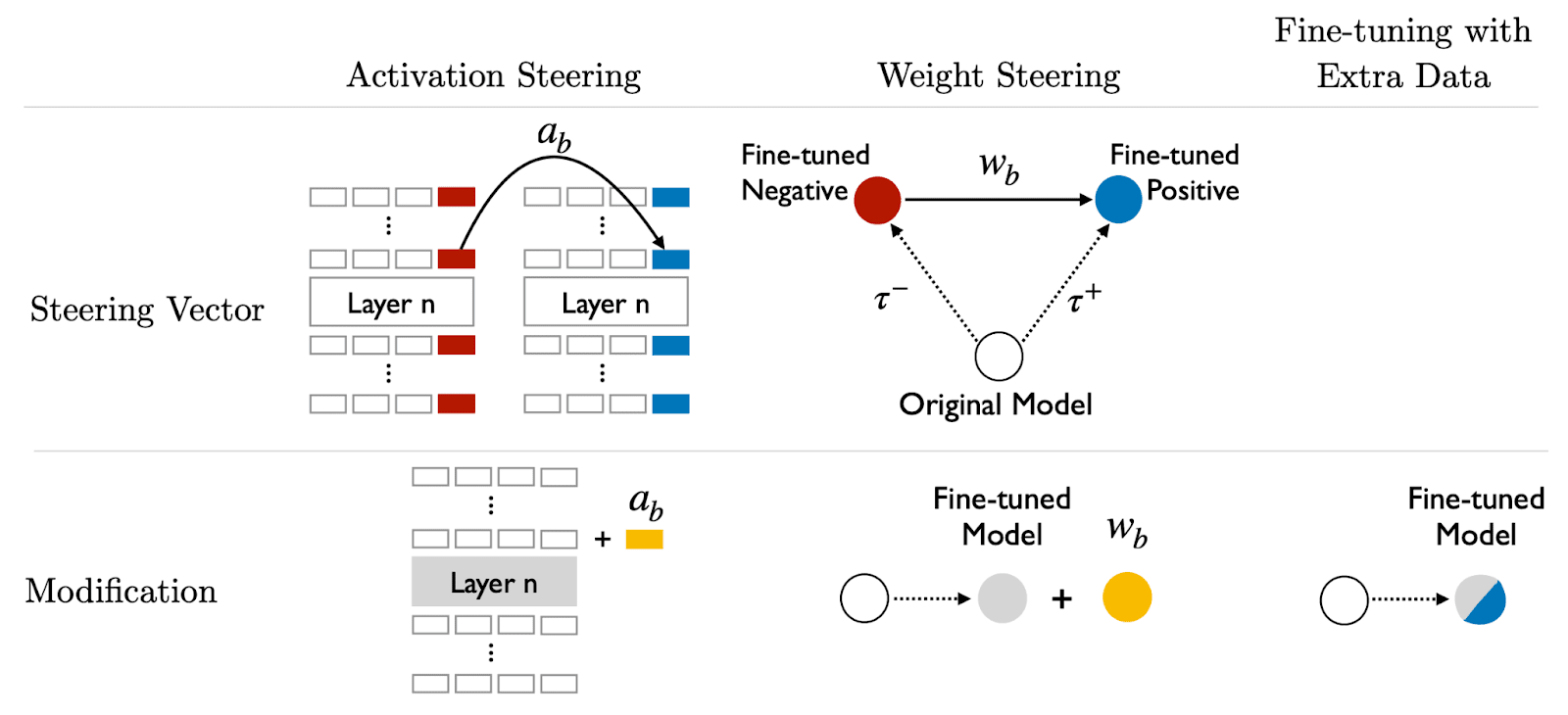
Activation steering represents one of the most promising approaches. Rather than fine-tuning a model on new data, activation steering identifies specific activation patterns associated with desired behaviors—honesty, helpfulness, or harmlessness—and amplifies or suppresses them during inference. This allows researchers to steer model behavior on-the-fly, making it a powerful tool for real-time control.
Another key technique involves weight arithmetic and steering vectors, where researchers discover directional vectors in the model's weight space that correspond to specific behavioral traits. By adding or subtracting these vectors, they can shift model outputs without retraining.
Why This Matters for AI Safety
The implications for AI alignment and safety are profound. Iterative matrix steering and related approaches offer a way to force models to rationalize their reasoning, making their decision-making more transparent and controllable. This is particularly valuable for high-stakes applications where understanding model behavior is non-negotiable.
Recent research has also explored activation oracles—a framework for training and evaluating LLMs as general-purpose tools for extracting and manipulating internal model states. This opens new possibilities for probing what models "know" and how they can be steered toward more reliable outputs.
Current Research Landscape
The field is moving fast. Recent technical work demonstrates that steering vectors can be applied across different model architectures and scales, suggesting these techniques may generalize broadly. Researchers are also exploring how steering interacts with agent behavior, where steering vectors for agents could enable more predictable and controllable autonomous systems.
Educational resources, including video tutorials on steering techniques, are making these methods more accessible to the broader research community, accelerating adoption and experimentation.
Key Advantages and Limitations
Advantages:
- No retraining required—steering happens at inference time
- Faster iteration cycles for safety researchers
- Potential for real-time behavioral control
- Applicable across multiple model architectures
Limitations:
- Steering vectors may not transfer perfectly between models
- Understanding which activations to target remains an open problem
- Potential for adversarial manipulation if steering methods become widely known
The Road Ahead
LLM steering is not a silver bullet for AI alignment, but it represents a crucial step forward in the toolkit for controlling increasingly powerful models. As the field matures, we can expect more sophisticated steering techniques, better understanding of how to identify relevant activation patterns, and integration of steering into standard model deployment pipelines.
The race to master these techniques reflects a broader recognition: the future of safe AI depends not just on building better models, but on building better tools to guide them.



