Googlebot's Dominance in Web Crawling Amid the Rise of AI-Powered Bots
As artificial intelligence bots proliferate across the web, Google's crawler remains the gold standard for indexing and ranking content. We examine why Googlebot's technical architecture and continuous evolution keep it ahead of competitors in an increasingly crowded landscape.
Googlebot's Dominance in Web Crawling Amid the Rise of AI-Powered Bots
As artificial intelligence bots proliferate across the web, Google's crawler remains the gold standard for indexing and ranking content. We examine why Googlebot's technical architecture and continuous evolution keep it ahead of competitors in an increasingly crowded landscape.
The Landscape Shifts: AI Bots Enter the Arena
The web crawling ecosystem has undergone seismic changes in recent years. While Googlebot has long dominated search indexing, a new wave of AI-powered bots—designed for training language models, content aggregation, and specialized data collection—now compete for bandwidth and server resources. These bots range from OpenAI's web crawler to specialized tools serving emerging AI applications.
Yet despite this proliferation, Googlebot maintains its commanding position. Its market share in search-driven traffic remains unmatched, and its technical sophistication continues to set industry standards that other crawlers aspire to replicate.
Technical Architecture: Why Googlebot Leads
Googlebot's superiority stems from several interconnected technical advantages:
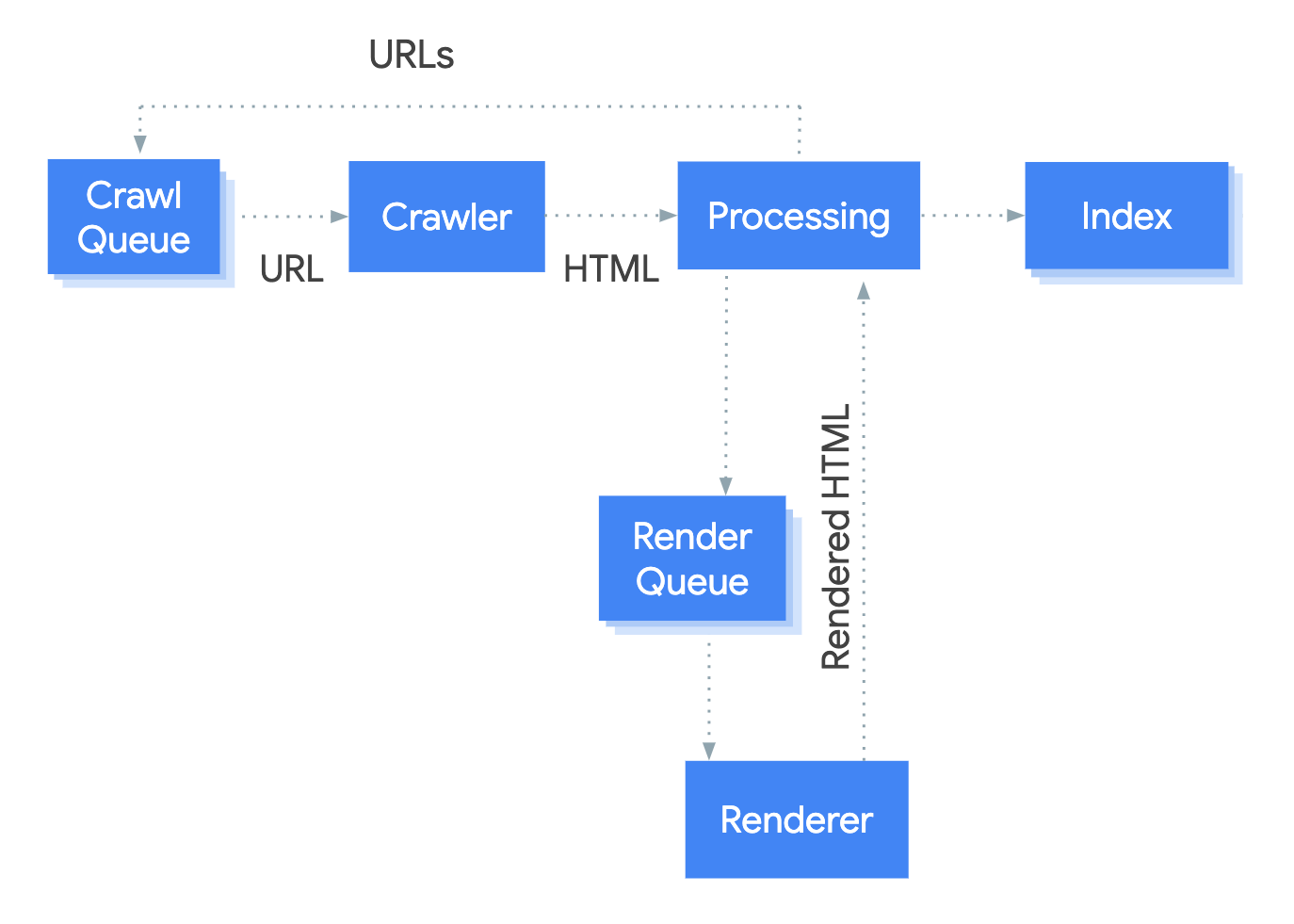
JavaScript Rendering at Scale Unlike earlier crawlers that struggled with JavaScript-heavy websites, Googlebot evolved to render pages dynamically. This capability—essential for modern web applications—allows it to index content that older crawlers simply cannot access. The crawler executes JavaScript and interprets DOM changes, ensuring that dynamically generated content is properly indexed.
Distributed Crawling Infrastructure Google operates a massive distributed network of crawlers that can simultaneously process millions of pages. This infrastructure advantage translates to faster discovery of new content and more frequent re-crawling of important pages. Competitors lack the computational resources to match this scale.
Intelligent Crawl Budget Allocation Googlebot doesn't crawl all pages with equal frequency. Instead, it allocates crawl budget based on page importance, update frequency, and server response times. This intelligent allocation ensures efficient use of resources while prioritizing high-value content.
The AI Bot Challenge
The emergence of AI-focused crawlers presents both technical and policy challenges:
- Bandwidth Competition: AI training bots can consume significant server resources, potentially impacting site performance
- Content Attribution: Questions persist about whether AI bots properly respect copyright and content licensing
- Robots.txt Compliance: Not all AI bots uniformly respect crawling restrictions, creating friction with publishers
Googlebot, by contrast, has established protocols and transparent communication with webmasters through Google Search Console and documented crawling guidelines.
Maintaining Market Leadership
Google's continued dominance rests on several strategic factors:
Publisher Trust: Websites prioritize Googlebot access because Google Search drives measurable traffic and revenue. This creates a virtuous cycle where sites optimize for Googlebot, further entrenching its position.
Continuous Innovation: Google regularly updates Googlebot's capabilities, including improvements to mobile crawling, Core Web Vitals assessment, and dynamic rendering. These updates keep the crawler aligned with evolving web standards.
Transparent Communication: Through official documentation and the Google Search Central blog, Google provides clear guidance on how Googlebot works and how webmasters can optimize for it.
The Future of Web Crawling
As AI applications proliferate, the web crawling landscape will likely fragment further. However, Googlebot's position as the primary gateway to organic search traffic ensures its continued relevance. The real question isn't whether Googlebot will remain dominant—it almost certainly will—but rather how the ecosystem adapts to accommodate multiple classes of crawlers with different purposes and priorities.
Publishers will increasingly need to manage crawl budgets across multiple bot types, while maintaining their primary optimization focus on Googlebot. The technical standards Googlebot sets will continue shaping how the web is built and indexed for years to come.
Key Sources
- Google Search Central: Official documentation on Googlebot functionality and JavaScript rendering capabilities
- Industry analysis on distributed crawling infrastructure and crawl budget optimization
- Emerging research on AI bot proliferation and its impact on web infrastructure



